Druid에 데이터를 적재하기 이전에 S3를 medallion structure 활용하여 작업하였다.
그리고 그 중에 골드데이터를 기준으로 드루이드에 데이터를 적재하는 과정을 진행해봤다.
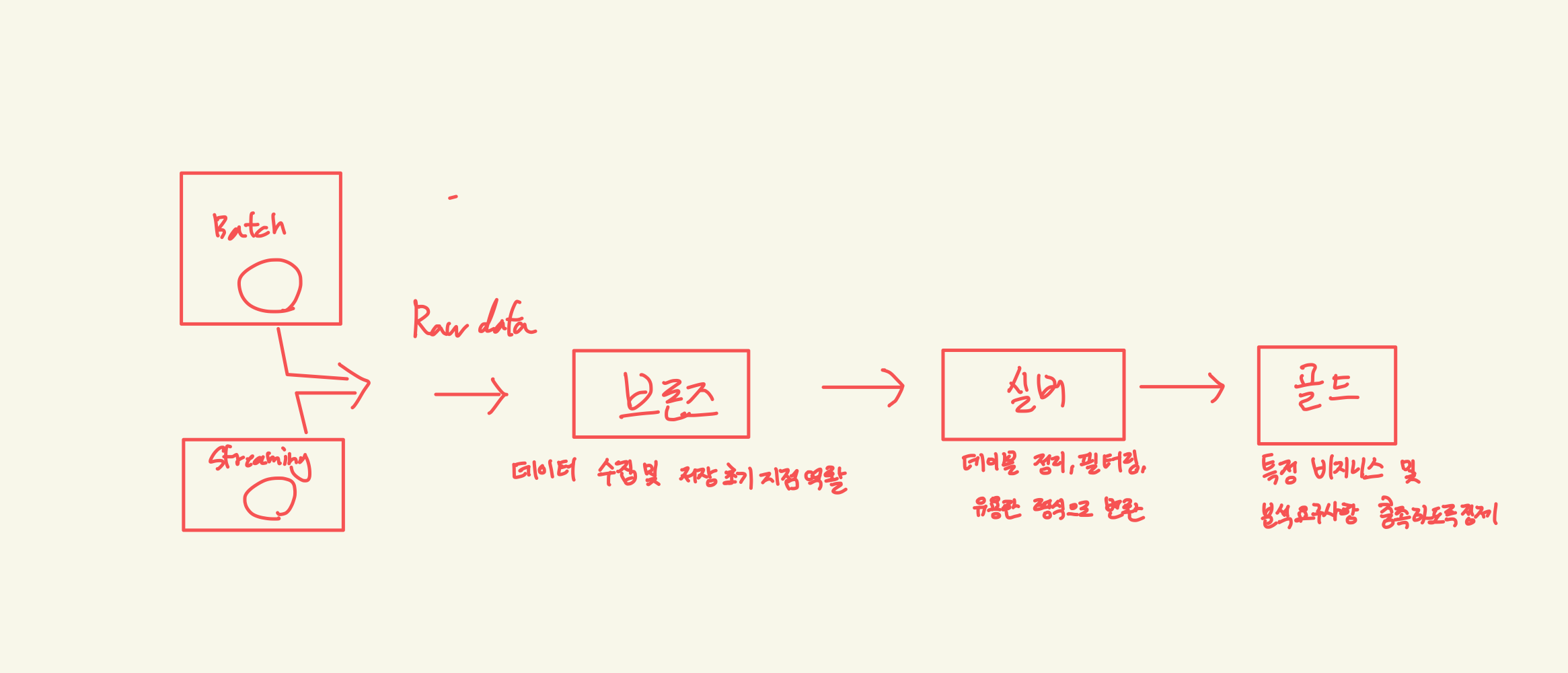
아래는 대략적으로 정리해보면 medallion structure 이다.
나의 경우 Druid는 local 버전으로 진행했음을 먼저 선언하고 간다
Druid에서 S3를 연결이 되는지를 확인한다. 우선 연결이 정상적으로 이뤄진다면 드루이드와 S3의 연결에는 문제가 없음을 확인했다.
그리고 연결하면서 S3 데이터에 대한 Spec JSON 를 추출할 수 있다.
해당 JSON 같은 경우에는 아래의 과정을 진행하면 된다.

위와 같이 처음부터 S3에 대한 스펙을 작성하기 보단, 위와 같은 방법으로 스켈레톤 JSON를 활용하면 더 빠르게 작업할 수 있을 것 같다고 생각한다
다음으로는 Druid 작업 스펙을 작성하는 방법인데 이 부분은 Druid Document를 참고하면 더 자세한 정보를 얻을 수 있다,
내가 작성한 Spec JSON에 대해서만 짤막하게 낙서한 부분이 있어 첨부하고자 한다.

위와 같이 자신의 Spec JSON를 정의하게 되면 Airflow를 활용하여 드루이드에 적재할 수 있게 Task를 작성할 수 있다.
나같은 경우에는 Airflow에서 지원하는 Druid Provider를 사용하다가 잘 안되는 부분들이 있었고,
이러한 부분을 직접 해당 Druid API 를 활용해 Druid 에게 나의 작업스펙를 작성하여 Submit 하는 방향으로 작업하였다.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
import requests,json
def post_to_druid():
# Druid 적재 작업 명세(JSON)의 위치
spec = {
"type": "index_parallel",
"spec": {
"ioConfig": {
"type": "index_parallel",
"inputSource": {
"type": "s3",
"prefixes": [
"s3://data-lake/gold/eventsim"
],
"filter": "*.parquet",
"properties": {
"accessKeyId": {
"type": "default",
"password": ""
},
"secretAccessKey": {
"type": "default",
"password": ""
}
}
},
"inputFormat": {
"type": "parquet"
}
},
"tuningConfig": {
"type": "index_parallel"
},
"dataSchema": {
"dataSource": "eventsim",
"granularitySpec": {
"type": "uniform",
"segmentGranularity": "DAY",
"queryGranularity": "HOUR",
"rollup": False
},
"timestampSpec": {
"column": "window.start",
"format": "auto"
},
"dimensionsSpec": {
"dimensions": [
"window.end",
"free_count",
"paid_count",
"female_count",
"male_count"
]
},
"metricsSpec": [
{
"type": "count",
"name": "count"
},
{
"type": "longSum",
"name": "free_count_sum",
"fieldName": "free_count"
},
{
"type": "longSum",
"name": "paid_count_sum",
"fieldName": "paid_count"
}
]
}
}
}
# Druid 적재 API 엔드포인트
druid_url = "http://192.168.1.229:8081/druid/indexer/v1/task"
headers = {
'Content-Type': 'application/json'
}
spec = json.dumps( spec )
try:
# HTTP POST 요청으로 Druid에 작업 명세 전송
response = requests.post(druid_url,headers=headers, data=spec)
response.raise_for_status() # 오류 발생 시 예외 발생
except requests.exceptions.HTTPError as http_err:
print(f"HTTP 오류 발생: {http_err}")
print(response.text)
except Exception as err:
print(f"오류 발생: {err}")
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1),
'retries': 1
}
with DAG('druid_s3_csv_ingestion', default_args=default_args, schedule_interval=None) as dag:
druid_task = PythonOperator(
task_id='post_to_druid',
python_callable=post_to_druid
)
druid_task
위와 같이 druid TASK를 작성하여 Airflow에서 실행하였고, 실제로 정상적으로 Druid에 잘 적재되는 것을 확인하였다..
'오픈소스' 카테고리의 다른 글
| [Spark] serializer 를 통한 성능개선 (0) | 2024.03.29 |
|---|---|
| [Spark] DockerCompose Airflow, PySpark DAG 실행하기 (0) | 2023.12.25 |
| 드루이드(druid) 튜토리얼 및 스크립트 분석 (0) | 2023.12.15 |
| M1으로 docker 로 설치하다 실패해 local로 설치하는 과정 (0) | 2023.12.15 |
| Eventsim으로 생성한 로그데이터로 SuperSet으로 시각화하기(4) (0) | 2023.12.07 |