내가 하고자 했던 것 => Docker Compose로 Airflow 구성 후에 Spark DAG를 생성하여 실행시키기
였고, 그 과정 속에서 상당히 많은 부분들을 추가하고 삽질이 필요하였다.
해당 과정 속에서 발생했던 트러블 중에 Airflow에서 Spark-submit이 정상적으로 전달이 되었지만
TaskSetManager 에서 무한대기 상태로 빠져버린다는 것이였다.
그 외에도 Airflow에 java 추가하기, Spark master, Worker 컨테이너 DockerFile 만드는 과정
등 여러 문제점들을 겪게 되었고, 해결하게 되는 과정들을 쭉 적어보려고 한다.
1. Connection
airflow 프로젝트는 공식 Git Repe를 참고하여 만들었다. 그 중에 Connection를 추가하기 위해서는
Provider에 대한 의존성을 추가해야한다. Docker-compose.yaml에 일 부분을 수정하면 된다.
_PIP_ADDITIONAL_REQUIREMENTS: ${_PIP_ADDITIONAL_REQUIREMENTS:- apache-airflow-providers-postgres apache-airflow-providers-apache-spark}
Git에서 내려받은 compose.yaml에 해당 파라미터를 찾아 apache-spark 추가 된 부분을 넣어주면 된다.
추가가 완료되면, airflow web UI에서 Admin > Connections > [+] 버튼을 눌러서 Spark Master와의 Connection를 추가해야 한다.

Docker Compose로 Local에서 실행환경 기준으로 거의 위와 같이 Host,Port를 넣어주면 되는 것으로 알고 있다.
Connection ID는 Spark Operation의 파라미터에 필요한 값이니 기억할 필요가 있다.
- Airflow Java 추가 ,Spark Worker,Master 도커 컴포즈에 추가하기
위에 언급하였듯, Airflow 공식 도커 컴포즈 파일을 활용하였다. 그리고 이 부분에서 적절한 커스텀마이징이 필요하였다.
특히 Spark를 활용하기 위해서 수정이 필수였다.
우선 sparkOperation 이 명령어를 하기 위해선 Java를 요구하였기에 Airflow를 위한 Dockerfile를 따로 하나 만들어줘야 했다.

위는 수정 전의 airflow Docker Compose File이다.
이 부분을 image 외에도 해당 컨테이너에 Java를 설치하고 환경변수를 추가해야 했다.
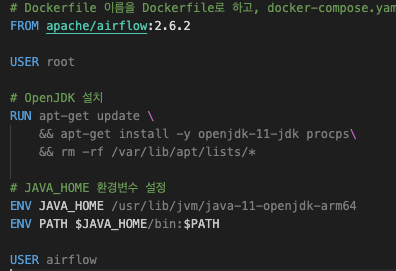
위와 같은 DockerFIle를 작성한 후에
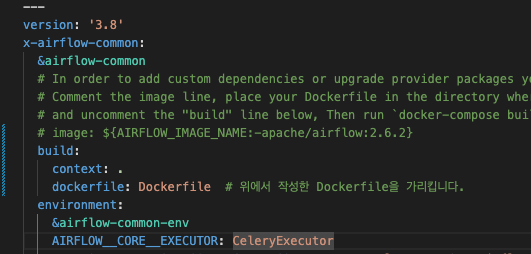
위와 같이 docker-compose.yaml 를 수정하면 된다.
그리고 추가적으로 service에 Spark 컨테이너들을 구성해야 한다.
전체적인 코드는 Git에 올려놓을 예정이니, 그 부분을 참고해보면 좋을 것 같다.
아무튼 위에 추가해준 사항들을 제외하고도, Spark를 컨테이너에 대한 구성하고 추가하는 부분에
상당한 애를 먹었다.
최종버전 이전에는 bitnami/spark의 컨테이너를 그대로 활용해서 worker,master 컨테이너를 만들었는데
분명 master 까지 submit이 이뤄지는 것으로 Log가 체크가 되는데 특정부분에서 무한대기 상태로 빠지게 되었다.
이 부분에 대한 점검 혹은 원인파악으로부터 너무 많은 시간이 소요되었고,
결국엔 명확한 원인파악이 되지 않았고, 추측되는 부분은 차용하고 있는 Spark image 컨테이너에 이슈가 있는 것으로
추측하였고 그로인해 DockerFile로 따로 작성하여 Spark 컨테이너를 구축했다.
결론적으로는 잘 해결되었지만 다른 문제들이 발생하였다.
3. TaskSetManager 이후에 무한대기 현상
위 과정까지 전반적으로 Spark의 구성이 끝났고 이후에 DAG를 실행하여 결과를 지켜보기로 했다.
20분이 지나도 작업이 끝나지 않아 확인해보니
[2023-12-25T06:39:10.508+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:10 INFO TaskSchedulerImpl: Adding task set 0.0 with 4 tasks resource profile 0
[2023-12-25T06:39:12.118+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:12 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.18.0.6:49528) with ID 0, ResourceProfileId 0
[2023-12-25T06:39:12.167+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:12 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (172.18.0.6:49530) with ID 1, ResourceProfileId 0
[2023-12-25T06:39:12.200+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:12 INFO BlockManagerMasterEndpoint: Registering block manager 172.18.0.6:39665 with 434.4 MiB RAM, BlockManagerId(0, 172.18.0.6, 39665, None)
[2023-12-25T06:39:12.244+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:12 INFO BlockManagerMasterEndpoint: Registering block manager 172.18.0.6:42191 with 434.4 MiB RAM, BlockManagerId(1, 172.18.0.6, 42191, None)
[2023-12-25T06:39:12.247+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:12 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (172.18.0.6, executor 0, partition 0, PROCESS_LOCAL, 7730 bytes)
[2023-12-25T06:39:12.273+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:12 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1) (172.18.0.6, executor 1, partition 1, PROCESS_LOCAL, 7763 bytes)위에 있는 로그에서 다음 프로세스로 넘어가지 않는 상황이 발생하고 있었다.
여기서 PySpark의 구조 상 TaskSetManager가 속한 부분을 도식화 해보면 아래와 같다.
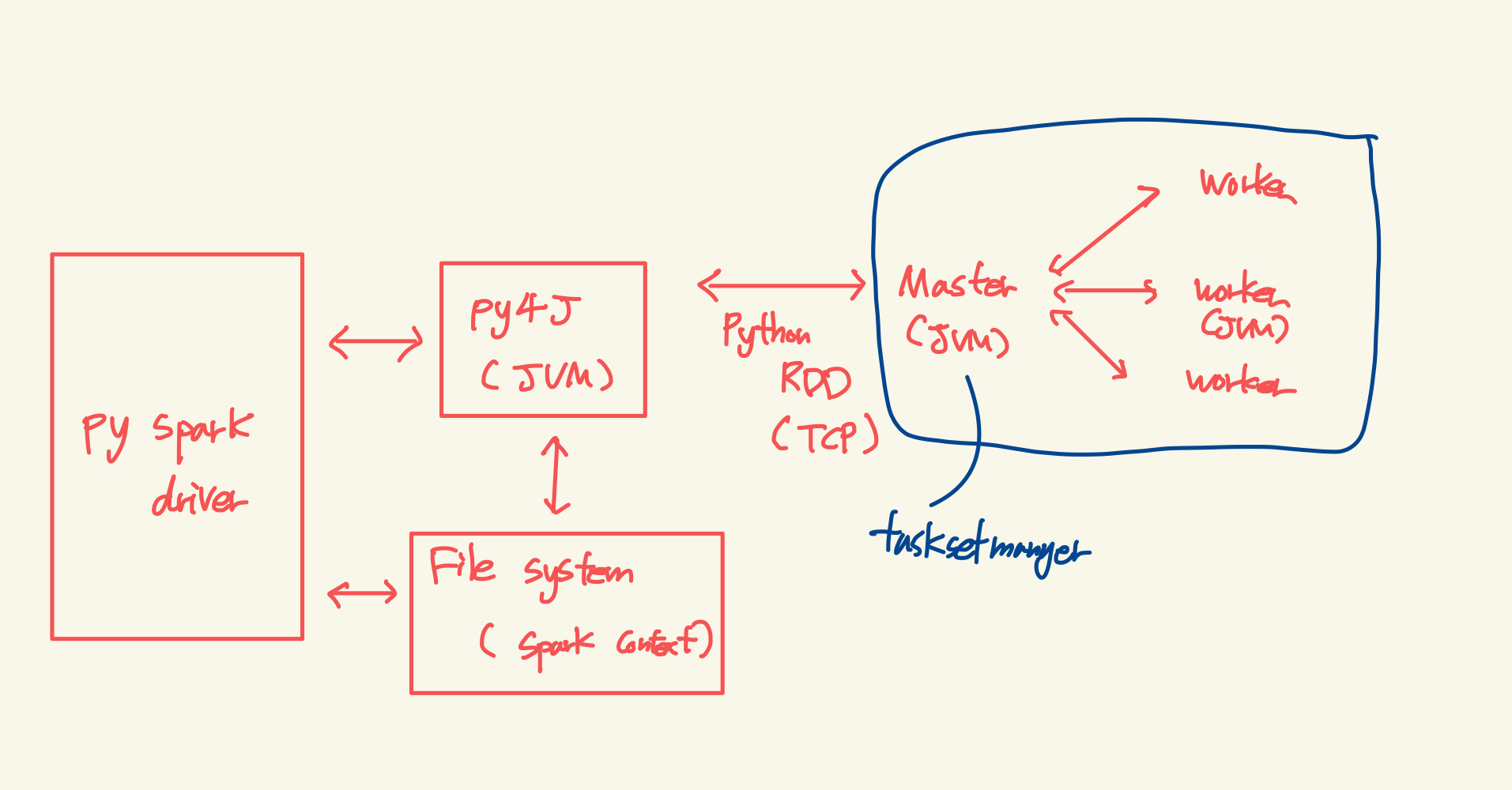
파란색 부분, 즉 Master 부분에서 더 이상 프로세스가 진행되고 있지 않는 상황이였다.
해당 부분을 모니터링 혹은 로깅을 하고 싶었지만 spark image로만 구성해놓은 상황이라 자세한 로깅 자체가
쉽질 않았다.
그래서 위에 있는 로그로만 가정해보기론 Spark 컨테이너 내부적인 Setting 혹은 init 자체에 대한 부분이
문제라고 생각했고, Git에 docker-compose로 작성한 spark 코드들을 찾아보면서 작성하였다.
작성 후 다시 DAG를 실행했을 때에도 동일한 문제가 발생하였다. 좌절할 뻔 했다. 해당 Log를 꼼꼼히 살펴보다 이상한 부분을
발견했다.
[2023-12-25T06:39:08.421+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO SparkContext: Running Spark version 3.5.0
[2023-12-25T06:39:08.423+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO SparkContext: OS info Linux, 5.10.124-linuxkit, aarch64
[2023-12-25T06:39:08.424+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO SparkContext: Java version 11.0.21
[2023-12-25T06:39:08.474+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[2023-12-25T06:39:08.531+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO ResourceUtils: ==============================================================
[2023-12-25T06:39:08.532+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO ResourceUtils: No custom resources configured for spark.driver.
[2023-12-25T06:39:08.533+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO ResourceUtils: ==============================================================
[2023-12-25T06:39:08.534+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO SparkContext: Submitted application: SparkTest
[2023-12-25T06:39:08.535+0000] {spark_submit.py:521} INFO - 23/12/25 06:39:08 INFO SparkContext: Spark configuration:
내가 Setting한 컨테이너에 Spark 버전은 3.4.2 이 였는데, SparkContext에서는 3.5.0으로 Running 중이라고 나온다.
위에 있는 상황에서 추측을 해보았다.
apache-airflow-providers-apache-spark 에서 이미 Spark 관련 버전이 Setting 되어있어 Submit 할 때
자동으로 Spark 버전을 맞춰서 보내는 것 같다.
위 추측으로 이것이 팩트인지를 찾기 위해 pyspark, airflow provider 관련 Document 를 찾아보기 시작했다.
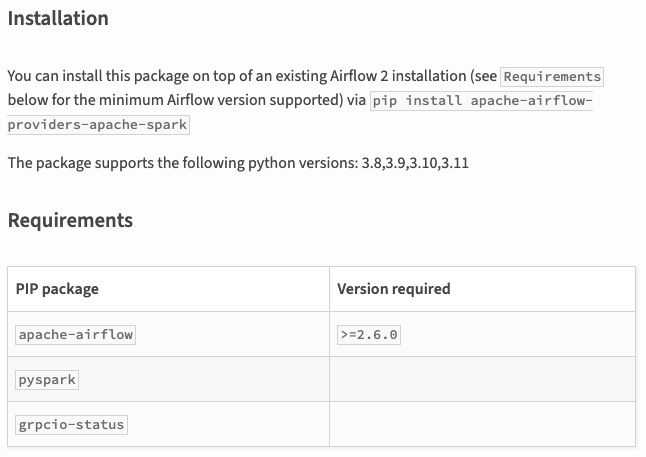
위에는 airflow provider 를 넣을 때, pip install 되면 의존되는 것들 중에 Pyspark가 존재한다.
즉 provider에 spark를 넣으면, pyspark가 자동으로 설치된다라는 소리이다.
그리고 해당 버전에 대해서는 크게 언급되어 있지 않을 것을 보니, latest 한 버전이 설치되는 것이고
그래서 자동으로 3.5.0 으로 설치됨을 추측해볼 수 있다.
pyspark 와 spark의 Version은 동일하다고 Document에서 찾아볼 수있 었고
그래서 위와 같이 버전을 spark 컨테이너 버전을 맞춰주고,
최종적으로는 Spark의 DAG를 Sucess 할 수 있었다.
'오픈소스' 카테고리의 다른 글
| [Spark] serializer 를 통한 성능개선 (0) | 2024.03.29 |
|---|---|
| [Airflow] Driud에 적재하는 task 작성하기 (0) | 2024.01.06 |
| 드루이드(druid) 튜토리얼 및 스크립트 분석 (0) | 2023.12.15 |
| M1으로 docker 로 설치하다 실패해 local로 설치하는 과정 (0) | 2023.12.15 |
| Eventsim으로 생성한 로그데이터로 SuperSet으로 시각화하기(4) (0) | 2023.12.07 |